Product Quantization for Nearest Neighbor Search
全文字数: 5526 字
阅读时间: 35 分钟
Notations
Vector quantization
量化是一种破坏性(destructive)过程,其目的是减少表示空间的基数。形式上,一个量化器(quantizer) 是一个函数 ,它将一个 维向量 映射到一个向量 ,其中索引集合 现在假设是有限的,即 。再现值(reproduction values) 被称为质心(centroids) 。再现值的集合 被称为码本(codebook) ,其大小为 。
映射到给定索引 的向量集合 被称为 (Voronoi)单元(cell),定义如下: 量化器的 个单元构成了 的一个划分。根据定义,所有位于同一单元 内的向量都由同一个质心 重构。量化器的质量通常通过输入向量 与其重构值 之间的均方误差(MSE, Mean Squared Error) 来衡量:
- 表示 和 之间的欧几里得距离
- 是对应于随机变量 的概率分布函数。
对于任意概率分布函数,通常使用蒙特卡洛采样(Monte-Carlo sampling) 进行数值计算,即在大量样本上计算 的平均值。
为了使量化器达到最优,它必须满足Lloyd 最优条件(Lloyd optimality conditions) 中的两个性质。
- 向量 必须被量化为最近的码本质心,即在欧几里得距离意义下: 因此,单元(cells)由超平面(hyperplanes) 划定。
- 重构值必须是 Voronoi 单元内向量的期望值,即:
Lloyd 量化器(Lloyd quantizer) 对应于 k-means 聚类算法,它通过迭代的方式寻找近似最优的码本,不断地将训练集中向量分配给质心,并从这些分配的向量中重新估计质心。需要注意的是,k-means 只能找到局部最优解,而非全局最优解(就量化误差而言)。
均方畸变(mean squared distortion) ,描述了当一个向量被重构到所属单元 的质心 时的误差。令: 表示一个向量被分配到质心 的概率,则该误差的计算公式如下: 均方误差(MSE)可以由这些量计算得到:
Product quantizers
乘积量化(Product quantization) 输入向量 被划分为 个不同的子向量 ,其中 ,每个子向量的维度为:
其中 是 的整数倍。这些子向量分别使用 个不同的量化器进行量化。因此,给定的向量 被映射如下:
其中 是与第 个子向量相关的低复杂度量化器。对于子量化器 ,关联索引集合 、码本 以及对应的重构值 。
乘积量化器的重构值由 乘积索引集合 的一个元素唯一标识:
因此,码本定义为笛卡尔积:
该集合的质心是 个子量化器的质心的串联。假设所有的子量化器都有相同的有限重构值数量 ,因此,总质心数为:
在极端情况下(当 ),向量 的每个分量都会被单独量化,此时 乘积量化器退化为标量量化器,其中每个分量的量化函数可能不同。
乘积量化器的优势在于可以通过多个小型质心集(子量化器的质心集合)来生成大规模质心集合。当使用 Lloyd 算法学习子量化器时,使用的样本数量有限,但码本仍然可以适应数据分布。
乘积量化器的学习复杂度是 倍于在 维度上进行 质心的 k-means 聚类的复杂度。
显式存储码本 并不高效,因此只存储所有子量化器的 个质心,即:
个浮点值。量化一个元素需要 次浮点运算。下表总结了 k-means、HKM 和乘积 k-means 的计算资源需求。乘积量化器 是唯一能在大 值时被索引存储于内存的方法。
| Method | Memory Usage | Assignment Complexity |
|---|---|---|
| k-means | ||
| HKM | ||
| Product k-means |
为了保证良好的量化性能,在 取常数时,每个子向量应具有相近的能量。一种方法是在量化前用随机正交矩阵变换向量,但对于大多数向量类型来说,这并不需要,也不推荐,因为相邻分量通常由于构造上的相关性而更适合使用相同的子量化器量化。
由于子空间正交,乘积量化器的平方畸变(Squared Distortion) 可计算为:
其中 是与子量化器 相关的畸变。
下图 显示了 MSE 随代码长度变化的曲线,其中代码长度为: ,是2的幂
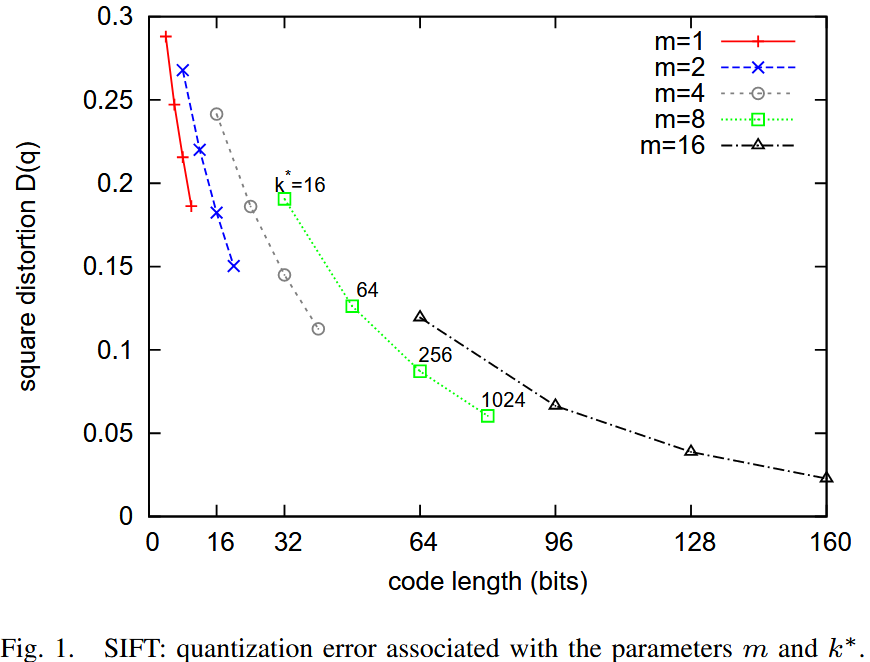
可以观察到,在给定比特数的情况下,使用少量子量化器,但每个子量化器有更多质心,比使用多个子量化器但每个子量化器比特数较少要更好。
在极端情况下(当 ),乘积量化器退化为标准 k-means 码本。
高 值 会增加量化器的计算成本(如表 I 所示),同时也增加了存储质心的内存开销(即 个浮点数)。如果质心查找表无法适应缓存,则效率会降低。
在 的情况下,为了保证计算开销可控,无法使用超过 16 位的编码。通常,选择 且 是一个合理的选择。
Search
Computing distances using quantized codes
假设有一个查询向量 和一个数据库向量 。有两种方法来计算这些向量之间的近似欧几里得距离:对称距离计算(SDC) 和 非对称距离计算(ADC)。
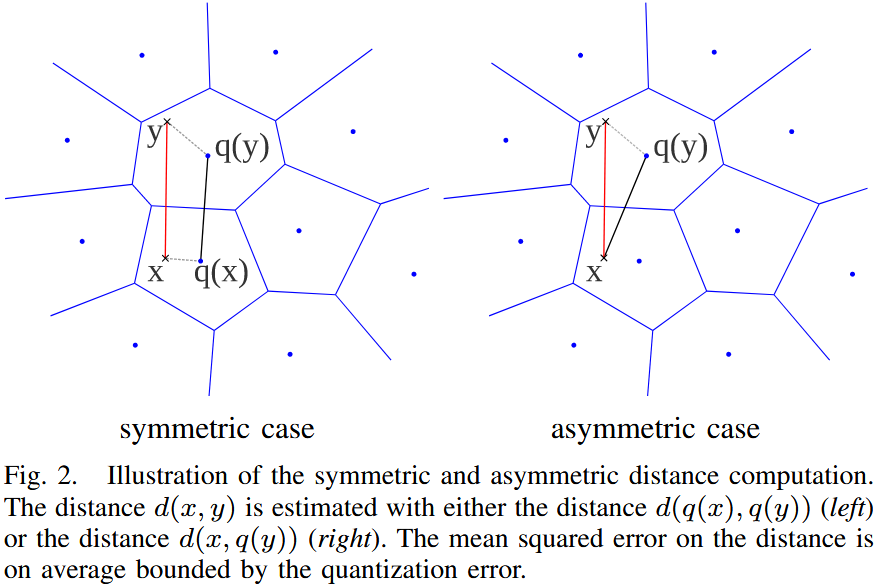
对称距离计算(Symmetric Distance Computation, SDC):
在 SDC 方法中,查询向量 和数据库向量 均由其对应的质心 和 表示。因此,距离 近似为:
利用 乘积量化器,这个距离可以高效地计算为:
其中,距离项 从查找表中读取,该查找表与第 个子量化器相关。每个查找表包含所有质心对 之间的平方距离,即存储了 个平方距离。
非对称距离计算(Asymmetric Distance Computation, ADC):
在 ADC 方法中,数据库向量 仍由其质心 表示,但查询向量 不经过编码。因此,距离 近似为:
其计算方式如下:
其中,平方距离 在搜索之前已经计算,其中 ,。
在最近邻搜索中,实际上不会计算平方根,直接使用平方距离进行排序。
下表 总结了在数据集中搜索最近邻所涉及的不同步骤的复杂度。假设数据集 的大小为 ,可以看到 SDC 和 ADC 的查询准备成本是相同的,并且不依赖于数据集大小 。
| SDC | ADC | |
|---|---|---|
| Encoding | ||
| Compute | ||
| Compute or | ||
| Find |
当 很大()时,计算量主要由求和运算决定。而搜索 个最小元素的复杂度 是对 的元素进行无序比较的平均复杂度。
SDC 与 ADC 的对比
| Pros | Cons | |
|---|---|---|
| SDC | 减少查询向量的内存开销 | 更高的距离畸变 |
| ADC | 更低的距离畸变 | 相对较高的查询向量内存开销 |
在本文的剩余部分,将重点讨论 ADC 方法。
Analysis of the distance error
分析使用 代替 所带来的距离误差。这一分析不依赖于乘积量化器,对满足 Lloyd 最优条件的任何量化器都适用。
在重构的均方误差(MSE)准则的基础上,距离畸变(distance distortion) 通过均方距离误差(MSDE) 来衡量:
根据三角不等式有:
同样地,可以写成:
可得:
最终得到:
其中, 是与量化器 相关的均方误差。
该不等式适用于任何量化器,表明本方法的距离误差在统计意义上受量化器的 MSE 约束。
对于 对称版本(SDC),类似的推导表明其误差在统计上受 约束。因此,最小化量化误差(MSE)是重要的,因为它可以作为距离误差的统计上界。
如果在最高排名的向量上执行精确距离计算(如 局部敏感哈希(LSH)),那么量化误差可以用作动态选择需要后处理的向量集合的标准,而不是随意选择某一部分向量。
Estimator of the squared distance
分析使用 或 进行估算时,如何在平均意义上低估描述符之间的距离。
该图显示了在 1000 个 SIFT 向量数据集中查询一个 SIFT 描述符所得的距离估计。该图比较了真实距离与SDC与ADC计算出的估计值。可以清楚地看到,这些距离估计方法存在偏差(bias),且对称版本(SDC)更容易受到偏差的影响。
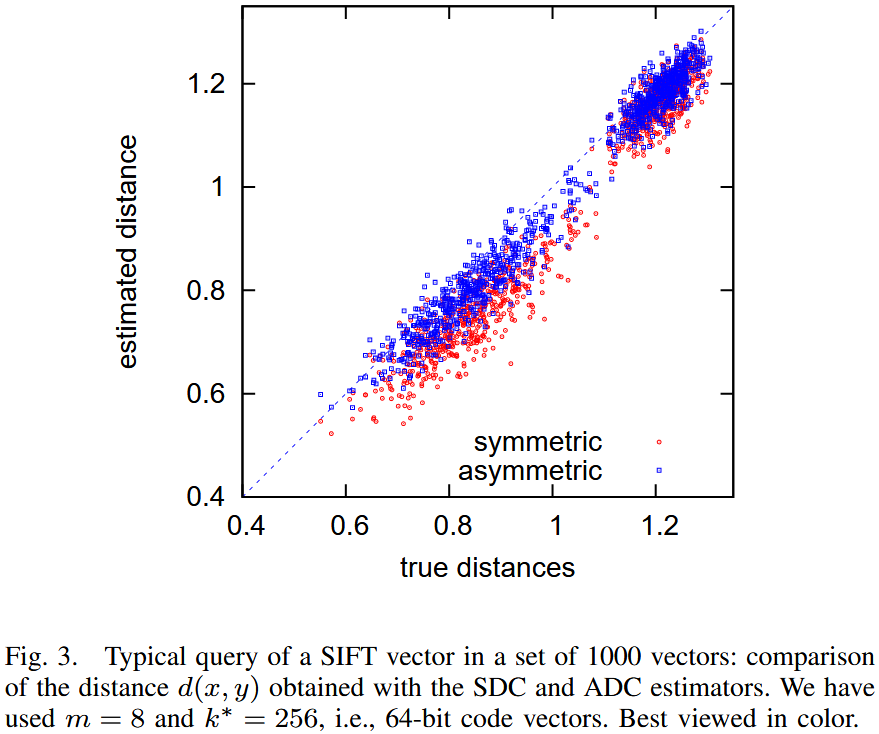
为了消除偏差,计算平方距离的期望值。在乘积量化方法中,一个给定向量 的近似值 由其子量化索引 (其中 )获得。
量化索引标识了向量 所处的单元 。因此,可以计算期望平方距离 作为修正项:
根据Lloyd 最优条件有:
因此可简化为:
其中, 代表了重构误差(distortion),即 由其重构值 近似时的误差。
在乘积量化框架下,向量 与 之间的期望平方距离可以通过修正方程 (13) 计算:
其中,修正项 为第 个子量化器的平均畸变(distortion):
这些畸变值可以预先学习,并存储在查找表中,供量化索引 使用。
对于 对称版本(SDC),即 和 均经过量化,类似的推导可以得到修正后的平方距离估计公式:
Discussion 该图显示了真实距离与估计距离之间的概率分布。该实验基于大规模 SIFT 描述符数据集。
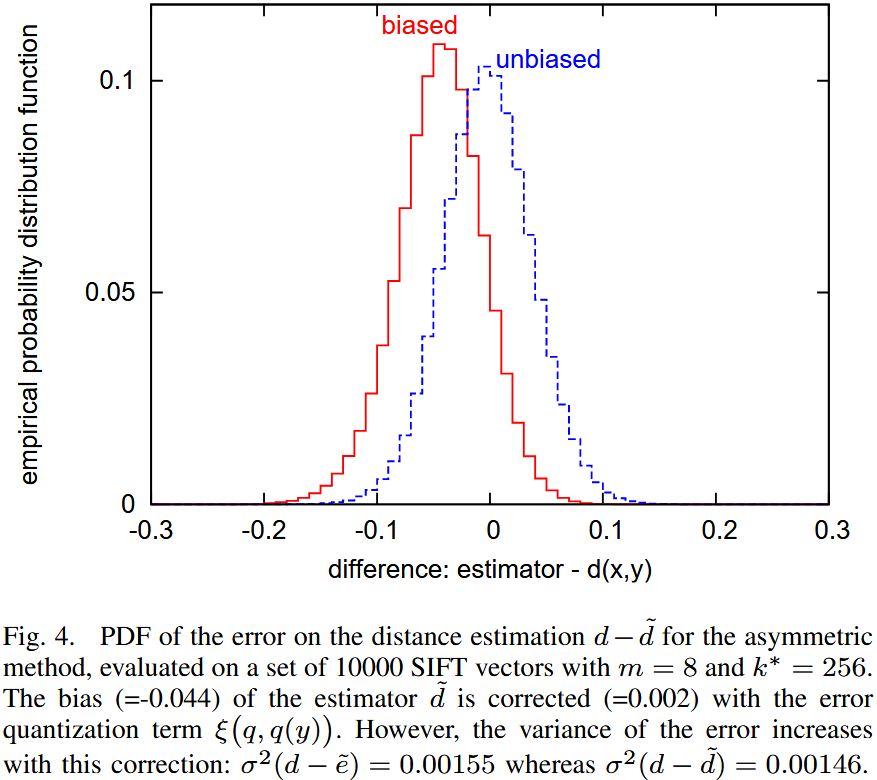
- 进行距离估计时,存在明显偏差。
- 采用 修正版本(,距离估计的偏差显著减少。
然而,修正偏差 会导致估计方差增大,这在统计学上是一个常见现象。此外,对于最近邻搜索而言:
- 修正项往往估计值更大,这可能会惩罚具有罕见索引的向量。
- 在 非对称版本(ADC) 中,修正项与查询 无关,只依赖于数据库向量 。
在实验中,修正方法在整体上效果较差,因此建议在最近邻搜索任务中使用原始版本,而修正版本仅在需要精准距离估计的任务中适用。
Avoid exhaustive search
使用乘积量化器进行近似最近邻搜索非常高效(每次距离计算仅需 次加法运算),并且大大减少了存储描述符所需的内存。然而,标准搜索方法是穷举式(Exhaustive)的。
为了避免穷举搜索:
- 倒排文件系统(Inverted File System, IVF)
- 非对称距离计算(ADC)
该方法称为 IVFADC。
传统倒排文件仅存储图像索引,而本文在此基础上增加了额外的编码,以便对每个描述符进行更精细的存储。使用乘积量化器对向量与其对应的粗质心之间的残差进行编码。
- 显著加速搜索过程,代价仅是每个描述符存储额外的少量比特/字节。
- 提高搜索精度,因为对残差进行编码比直接编码向量本身更加精确。
Coarse quantizer, locally defined product quantizer
码本(codebook)是通过 k-means 学习得到的,并生成了一个量化器 ,在后续内容中称为 粗量化器(coarse quantizer)。对于 SIFT 描述符,与 相关的质心(centroid)数量 通常在 1000 到 1000000 之间。因此,与 乘积量化器相比,粗量化器的规模较小。
除了粗量化器,还使用乘积量化器对向量的描述进行细化。具体来说,粗量化器 生成的质心可以提供全局信息,但仍需进一步编码残差信息,因此使用 乘积量化器 对残差向量进行编码:
其中,残差向量 表示 Voronoi 单元中的偏移量。由于残差向量的能量相比原始向量要小,因此存储其量化信息的代价也较低。
向量 可被近似表示为:
它可以用元组 来表示。
类比于二进制表示的概念:
- 粗量化器() 提供的是最高有效位(MSB),用于大致定位向量。
- 乘积量化器() 提供的是最低有效位(LSB),用于精细校正残差信息。
查询向量 和数据库向量 之间的距离可以近似计算为 :
令 表示第 个子量化器(Subquantizer),则可分解计算该距离:
类似于 ADC(Asymmetric Distance Computation) 策略,对于每个子量化器 ,预计算部分残差向量 与所有质心 之间的距离,并存储这些值。
乘积量化器是在一个学习集合中通过残差向量训练得到的。虽然向量最初由粗量化器映射到不同的索引,但最终的残差向量被用于训练一个统一的乘积量化器。
假设当残差在所有 Voronoi 单元上进行边际化(Marginalization)时,相同的乘积量化器仍然有效。然而,这种方法的效果可能不如为每个 Voronoi 单元单独训练一个独立的乘积量化器,但后者的计算成本极高。如果要为每个 Voronoi 单元分别训练乘积量化器,则需要存储 个乘积量化码本,即:
个浮点值。这对于典型的 值来说,将会导致极高的存储需求,在实际应用中难以承受。
Indexing structure
使用粗量化器(coarse quantizer)来实现一种倒排文件结构(inverted file structure),它被组织成一个包含列表的数组 。如果 是要索引的向量数据集,那么与质心 相关联的列表 将存储集合 。
在倒排列表 中,与 相关的条目包含一个向量标识符(vector identifier)和编码后的残差 :
| field | length(bits) |
|---|---|
| identifier | 8–32 |
| code |
标识符字段是倒排文件结构带来的开销。根据存储向量的不同特性,标识符不一定是唯一的。例如,在使用局部描述符(local descriptors)表示图像时,图像标识符可以替代向量标识符,即同一张图像的所有向量都可以使用相同的标识符。因此,20 位的标识符字段足以在一个包含一百万张图像的数据集中唯一标识一张图像。
通过索引压缩(index compression)可以进一步降低存储开销,使存储标识符的平均成本降低到约 8 比特,具体取决于参数。
Search algorithm
倒排文件(inverted file)是非穷尽(non-exhaustive)的关键。当搜索向量 的最近邻时,倒排文件提供了一个 的子集,用于计算距离:仅扫描与 对应的倒排列表 。
然而, 及其最近邻通常不会被量化到同一个质心,而是被量化到相邻的质心。为了解决这个问题,采用 多重分配(multiple assignment) 策略 。查询向量 被分配到 个索引,而不是仅仅一个索引,这些索引对应于 代码本 中 的 个最近邻。然后,扫描所有相应的倒排列表。多重分配不会用于数据库向量,因为这会增加内存占用。
下图概述了数据库的索引和搜索过程。
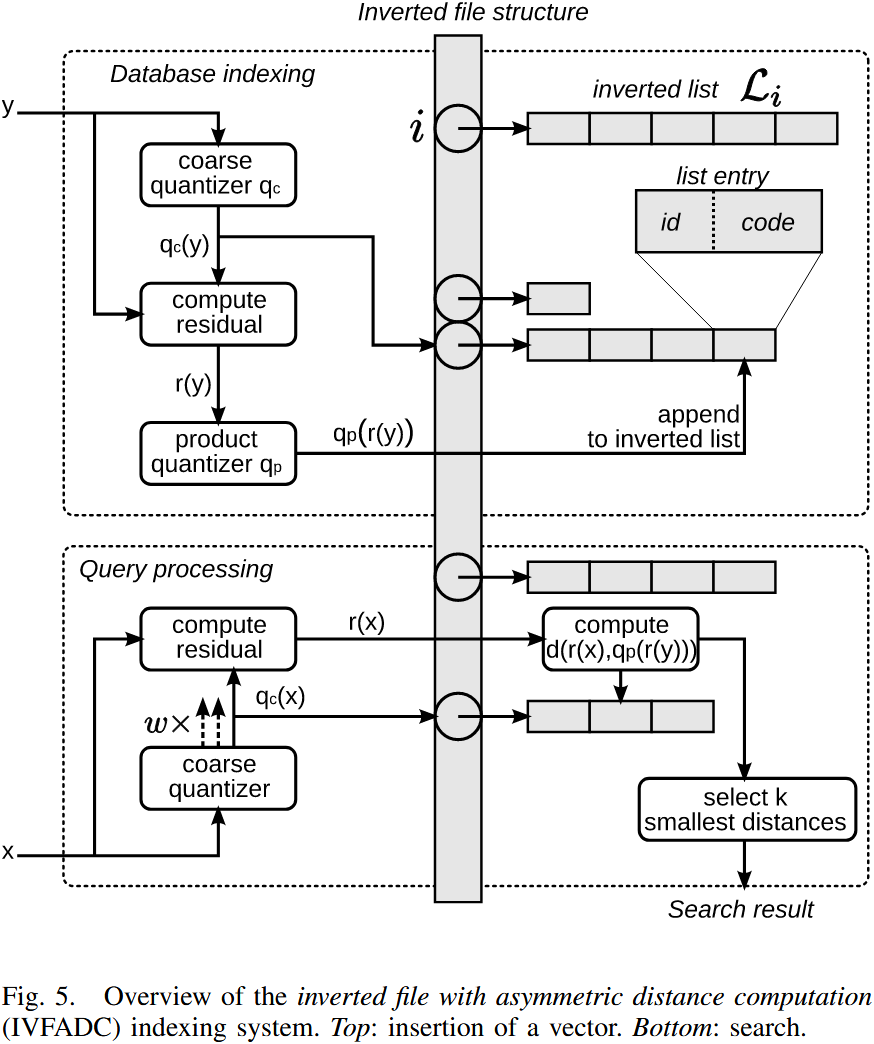
索引(Indexing)向量 的过程如下:
- 对 进行量化,得到 ;
- 计算残差(residual):;
- 对残差 进行量化,得到 ,对于乘积量化器(product quantizer),这意味着将 映射到 ,其中 ;
- 向倒排列表 添加新条目,该条目包含 向量(或图像)标识符 和 二进制编码(即乘积量化器的索引)。
查询(Searching)最近邻 的过程如下:
-
将 量化到代码本 中最近的 个质心;
为了便于表述,接下来的两步中简单地用 来表示与这些 个分配相关的残差。这两个步骤适用于所有 个分配。
-
计算平方距离 ,对于每个子量化器 以及其所有质心 ;
-
计算 与倒排列表中所有索引向量的平方距离;
使用上一步计算的子向量到质心距离,最终得到总距离。这一过程涉及查找 个预计算值(见公式 31)。
-
根据估计距离选择 个最近邻:
- 这一过程使用 最大堆(Maxheap) 结构(固定容量)来存储 当前已找到的 个最小距离;
- 每次计算距离后,仅当该点的距离小于最大堆中当前的最大距离时,才将其插入数据结构。
只有第 3 步 依赖于数据库的大小。与 ADC(Asymmetric Distance Computation,非对称距离计算) 相比,额外的 量化 到 仅涉及计算 个 D 维向量的距离。假设倒排列表是均衡的,则需要解析 个条目。因此,该搜索方法比 ADC 显著更快。